随着大模型的兴起,NLP的模型应用上也迎来了巨大的变革。最近在研究大语言模型结构时,发现对Transformer的某些细节理解模糊,本文回顾具有划时代意义的Transformer。 从理论和代码方向整体回顾一遍。
整体架构
模型输入
编码器部分
解码器部分
Transformer之前的主流序列转录模型(序列进序列出,例如机器翻译、信息抽取等),一般是基于复杂的RNN/CNN的encoder-decoder架构,如GRU、LSTM等。随后,为了更有效的利用参数,在编码器和解码器的交互中,通常会加入一个attention机制,以得到更优的结果。简单的 网络架构,仅基于注意力机制,完全抛弃了循环和卷积网络。使得模型更易于并行训练从而大大减少训练时间。且在一些机器翻译任务上得到了更优的结果。直至如今,Transformer架构依旧被大规模的用在各种主流的模型中。
在Transformer提出前,处理序列任务的主流模型是基于RNN的Encoder-Decoder。
由于RNN的时序特点,后一步需要用到前一步的计算结果,导致序列无法高效并行。
RNN使用共享权值矩阵,在面临较长序列时,会有梯度消失的问题(也可以说是后面词的梯度会覆盖前面的梯度)。即使后序的LSTM和GRU对这一部分做了改进,但也无法完全解决该问题。
对于CNN架构的模型,在处理序列问题时,由于感受野问题,使得其在处理长序列问题时,具有局限性。
Transformer模型, 只利用self-Attention,去掉CNN、RNN,解决了上面提到的局限性。整体的模型架构如下图所示(该图摘自-动手学深度学习Pytorch版):先对整体架构做简单说明及完成整体架构的代码实现,具体的实现细节在后续的小节中进行详细说明。 Encoder :输入是单词的Embedding,与位置编码相加,然后进入Encoder层,编码器是由多个Encoder层堆叠而成。每一层又可以分成Attention层和全连接层,再额外加了残差及Layer Normalization。Decoder :第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入多个decoder层堆叠的解码器。输出 :最后的输出要通过Linear层(全连接层),再通过softmax做预测。NLP-tutorial 的基础上进行修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class EncoderLayer (nn.Module ): """编码层""" def __init__ (self ): super(EncoderLayer, self).__init__() def forward (self ): """前向""" pass class DecoderLayer (nn.Module ): """解码层""" def __init__ (self ): super(DecoderLayer, self).__init__() def forward (self ): """前向""" pass class Encoder (nn.Module ): """多层堆叠编码器""" def __init__ (self ): super(Encoder, self).__init__() def forward (self ): """前向""" pass class Decoder (nn.Module ): """多层堆叠解码器""" def __init__ (self ): super(Decoder, self).__init__() def forward (self ): """前向""" pass class Transformer (nn.Module ): """Transformer的整体架构""" def __init__ (self ): """ 整体3个模块组成: 1. 编码器 2. 解码器 3. 全连接输出层 """ super(Transformer, self).__init__() self.encoder = Encoder().cuda() self.decoder = Decoder().cuda() self.full_connect = nn.Linear().cuda() def forward (self ): """前向""" pass
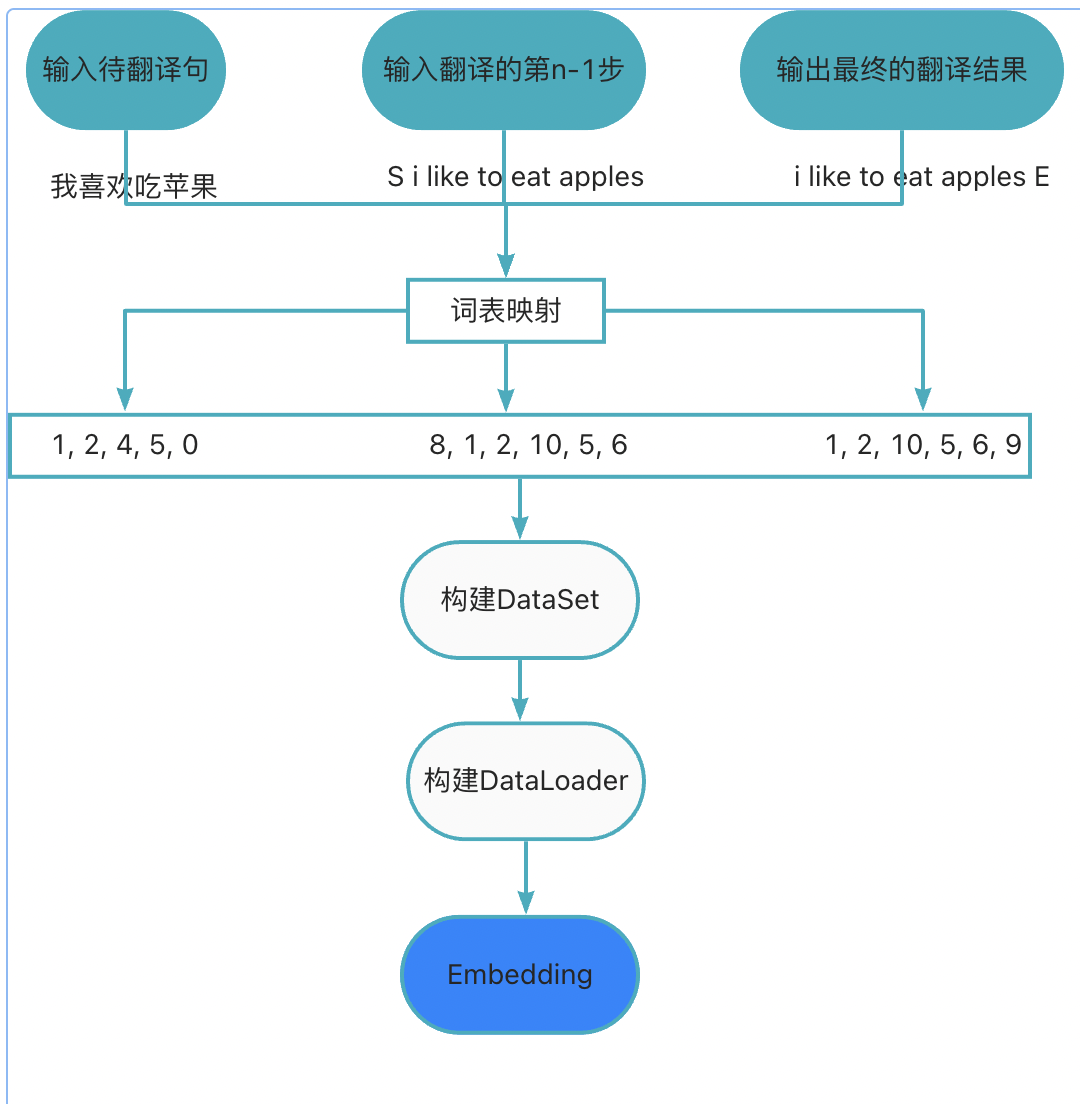
如下图所示,这一步主要是将输入、输出的文本通过vocab映射为编号,然后构建适用于后续训练的DataSet及DataLoader的过程。这里主要涉及一个Padding操作,及把输入输出句子的长度对齐,不足的补0,超过长度的截断。PyTorch的Dataloader和Dataset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import mathimport torchimport numpy as npimport torch.nn as nnimport torch.optim as optimimport torch.utils.data as Datasrc_len = 5 tgt_len = 8 d_model = 512 d_ff = 2048 d_k = d_v = 64 n_layers = 6 n_heads = 8 batch_size = 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import torchimport torch.utils.data as Datasentences = [ ['我 喜欢 吃 苹果 P' , 'S i like to eat apples P P' , 'i like to eat apples P P E' ], ['我 不 喜欢 吃 橘子' , 'S i do not like to eat oranges' , 'i do not like to eat oranges E' ]] source_vocab = {'P' : 0 , '我' : 1 , '喜欢' : 2 , '不' : 3 , '吃' : 4 , '苹果' : 5 , '橘子' : 6 } source_vocab_size = len(source_vocab) target_vocab = {'P' : 0 , 'i' : 1 , 'like' : 2 , 'do' : 3 , 'not' : 4 , 'eat' : 5 , 'apples' : 6 , 'oranges' : 7 , 'S' : 8 , 'E' : 9 , 'to' : 10 } idx2word = {i: w for i, w in enumerate(target_vocab)} target_vocab_size = len(target_vocab) def make_data (sentences ): """构建训练集""" enc_inputs, dec_inputs, dec_outputs = [], [], [] for i in range(len(sentences)): enc_input = [[source_vocab[n] for n in sentences[i][0 ].split()]] dec_input = [[target_vocab[n] for n in sentences[i][1 ].split()]] dec_output = [[target_vocab[n] for n in sentences[i][2 ].split()]] enc_inputs.extend(enc_input) dec_inputs.extend(dec_input) dec_outputs.extend(dec_output) return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs) class TransDataSet (Data.Dataset ): """OwnDataSet,主要实现以下3个内置函数""" def __init__ (self, enc_inputs, dec_inputs, dec_outputs ): super().__init__() self.enc_inputs = enc_inputs self.dec_inputs = dec_inputs self.dec_outputs = dec_outputs def __len__ (self ): return self.enc_inputs.shape[0 ] def __getitem__ (self, idx ): return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx] enc_inputs, dec_inputs, dec_outputs = make_data(sentences) loader = Data.DataLoader(TransDataSet(enc_inputs, dec_inputs, dec_outputs), batch_size=batch_size, shuffle=True )
Tokenizor简介一(BPE原理及python实现)
num_embeddings:查询表的大小
embedding_dim:每个查询向量的维度
将对应的预处理input转化为Embedding,只需调用该函数即可,具体实现如下所示:
1 src_emb = nn.Embedding(src_vocab_size, d_model)
位置编码在后续基于Transformer架构的文章中有很多变体,在Bert及GPT系列中都有不同的实现方式,尤其是在大语言模型大行其道的现在,在面对长token的输入时,挑选合适的位置编码也会提升训练的效果。几种常用的位置编码介绍及pytorch实现
为避免数值计算时的溢出需要对1000 0 2 i / d 10000^{2i/d} 1 0 0 0 0 2 i / d
由于位置编码不需要训练,所以实现时需要使用register_buffer函数将其注册为属性,避免计算梯度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class PositionalEncoding (nn.Module ): """位置编码""" def __init__ (self, d_model, dropout=0.1 , max_len=5000 ): super().__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0 , max_len, dtype=torch.float).unsqueeze(1 ) div_term = torch.exp(torch.arange(0 , d_model, 2 ).float() * (-math.log(10000.0 ) / d_model)) pe[:, 0 ::2 ] = torch.sin(position * div_term) pe[:, 1 ::2 ] = torch.cos(position * div_term) pe = pe.unsqueeze(0 ).transpose(0 , 1 ) self.register_buffer('pe' , pe) def forward (self, x ): ''' x: [seq_len, batch_size, d_model] ''' x = x + self.pe[:x.size(0 ), :] return self.dropout(x)
如下图所示:将Embedding与位置编码相加即可送入编码层,进行后续的训练。上述实现中通过在PositionalEncoding的forward函数中相加。
编码器主要负责将Transformer模型中的输入文本进行更好的编码,可以作为特征处理器单独使用,在Bert系列的模型中,只使用了编码器部分,通过构造类似完形填空的mask任务来训练模型。
Attention(注意力机制)
Self-Attention(自注意力机制)
MultiHead-Attention (多头注意力)
The Residuals(残差连接)
PoswiseFeedForwardNet(基于位置的前馈网络)
LayerNorm (层归一化)
本节详细的对编码器内容进行总结,并使用代码实现(代码主要参考了动手学深度学习)辅助理解。
从图中可以看出,输入层的向量进入编码层会首先进入一个多头注意力层,这里详细总结注意力的相关知识。
在Transformer出现之前,解决序列相关的NLP任务时,主流的模型大部分是基于循环神经网络(RNN),但RNN有个致命的问题-梯度消失。当输入的序列长度过长时,模型会逐渐遗忘靠前序列的信息。Bahdanau 等人在2015年提出最初的注意力方案。其核心思想在于,模型希望在解码时能够根据编码元素间不同的重要性参考编码阶段的记忆。深度学习中的注意力模型(2017版) 。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self-Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
a ( q , k ) = w v ⊤ tanh ( W q q + W k k ) ∈ R , a(\mathbf q, \mathbf k) = \mathbf w_v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R}, a ( q , k ) = w v ⊤ tanh ( W q q + W k k ) ∈ R , W q ∈ R h × q \mathbf W_q\in\mathbb R^{h\times q} W q ∈ R h × q W k ∈ R h × k \mathbf W_k\in\mathbb R^{h\times k} W k ∈ R h × k w v ∈ R h \mathbf w_v\in\mathbb R^{h} w v ∈ R h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class AdditiveAttention (nn.Module ): """加性注意力""" def __init__ (self, key_size, query_size, num_hiddens, dropout, **kwargs ): super(AdditiveAttention, self).__init__(**kwargs) self.W_k = nn.Linear(key_size, num_hiddens, bias=False ) self.W_q = nn.Linear(query_size, num_hiddens, bias=False ) self.w_v = nn.Linear(num_hiddens, 1 , bias=False ) self.dropout = nn.Dropout(dropout) def forward (self, queries, keys, values, valid_lens ): queries, keys = self.W_q(queries), self.W_k(keys) features = queries.unsqueeze(2 ) + keys.unsqueeze(1 ) features = torch.tanh(features) scores = self.w_v(features).squeeze(-1 ) self.attention_weights = masked_softmax(scores, valid_lens) return torch.bmm(self.dropout(self.attention_weights), values)
Transformer中使用了这种注意力的方式,使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度d d d d d d d \sqrt{d} d W Q W^Q W Q W K W^K W K W V W^V W V X X X Q , K , V Q,K,V Q , K , V Z Z Z
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class ScaledDotProductAttention (nn.Module ): """缩放点积注意力""" def __init__ (self ): super().__init__() def forward (self, Q, K, V, attn_mask ): ''' Q: [batch_size, n_heads, len_q, d_k] K: [batch_size, n_heads, len_k, d_k] V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask: [batch_size, n_heads, seq_len, seq_len] ''' scores = torch.matmul(Q, K.transpose(-1 , -2 )) / np.sqrt(d_k) scores.masked_fill_(attn_mask, -1e9 ) attn = nn.Softmax(dim=-1 )(scores) context = torch.matmul(attn, V) return context, attn
注意: 这里的attn_mask主要是为了在解码时对后时刻的token进行过滤,在解码层时会进一步解释。
为了提取更多的特征,原文将自注意力拆分为多头的自注意力,有点实验科学的意思。结果确实比单个的注意力要好,原文中的实验数据如下图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class MultiHeadAttention (nn.Module ): """多头自注意力""" def __init__ (self ): super().__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False ) self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False ) self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False ) self.fc = nn.Linear(n_heads * d_v, d_model, bias=False ) def forward (self, input_Q, input_K, input_V, attn_mask ): ''' input_Q: [batch_size, len_q, d_model] input_K: [batch_size, len_k, d_model] input_V: [batch_size, len_v(=len_k), d_model] attn_mask: [batch_size, seq_len, seq_len] ''' residual, batch_size = input_Q, input_Q.size(0 ) Q = self.W_Q(input_Q).view(batch_size, -1 , n_heads, d_k).transpose(1 ,2 ) K = self.W_K(input_K).view(batch_size, -1 , n_heads, d_k).transpose(1 ,2 ) V = self.W_V(input_V).view(batch_size, -1 , n_heads, d_v).transpose(1 ,2 ) attn_mask = attn_mask.unsqueeze(1 ).repeat(1 , n_heads, 1 , 1 ) context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) context = context.transpose(1 , 2 ).reshape(batch_size, -1 , n_heads * d_v) output = self.fc(context) return nn.LayerNorm(d_model).cuda()(output + residual), attn
在实现多头自注意力时需要注意以下几点:
如下图所示,多头并没有增加额外的参数,只是把参数按照头数分割。注意力模块的维度为[d_model,d_k * n_heads]
维度变换需要特别注意,以免矩阵相乘出错。
这两者都是构建有效的深度架构的关键,尤其是在模型的网络结构很深的情况下。
1 2 3 4 5 6 7 8 class AddNorm (nn.Module ): """残差连接后进行层规范化""" def __init__ (self, normalized_shape, **kwargs ): super(AddNorm, self).__init__(**kwargs) self.ln = nn.LayerNorm(normalized_shape) def forward (self, X, Y ): return self.ln(self.dropout(Y) + X)
本质上是两个全连接层,由于其对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),所以称前馈网络是_基于位置的_(positionwise)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class PoswiseFeedForwardNet (nn.Module ): """基于位置的前馈网络""" def __init__ (self ): super(PoswiseFeedForwardNet, self).__init__() self.fc = nn.Sequential( nn.Linear(d_model, d_ff, bias=False ), nn.ReLU(), nn.Linear(d_ff, d_model, bias=False ) ) def forward (self, inputs ): ''' inputs: [batch_size, seq_len, d_model] ''' residual = inputs output = self.fc(inputs) return nn.LayerNorm(d_model).cuda()(output + residual)
介绍完全部的子结构后,将所有子结构组合为编码层。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class EncoderLayer (nn.Module ): """编码层""" def __init__ (self ): super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward (self, enc_inputs, enc_self_attn_mask ): ''' enc_inputs: [batch_size, src_len, d_model] enc_self_attn_mask: [batch_size, src_len, src_len] ''' enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) enc_outputs = self.pos_ffn(enc_outputs) return enc_outputs, attn
将多个编码层组合为编码器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Encoder (nn.Module ): def __init__ (self ): super(Encoder, self).__init__() self.src_emb = nn.Embedding(source_vocab_size, d_model) self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward (self, enc_inputs ): ''' enc_inputs: [batch_size, src_len] ''' enc_outputs = self.src_emb(enc_inputs) enc_outputs = self.pos_emb(enc_outputs.transpose(0 , 1 )).transpose(0 , 1 ) enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) enc_self_attns = [] for layer in self.layers: enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) return enc_outputs, enc_self_attns
这里需要注意的是:
如下图所示,解码器的结构与编码器大致相同,也是由多个相同的层组成。每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。与编码器的主要不同点有以下2个:
在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。因此,在任何解码器时间步中,只有生成的词元才能用于解码器的自注意力计算中。为了在解码器中保留自回归的属性,掩蔽自注意力设定了参数attn_mask,以便任何查询都只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算。
解码时只能关注到时间步之前的信息。为了进行并行运算,这里使用一个上三角矩阵表示需要mask的区域,如下图所示:输入一个序列长度为4的句子,自注意力计算时的mask区域为图中标为1的区域
1 2 3 4 5 6 7 8 9 def get_attn_subsequence_mask (seq ): ''' seq: [batch_size, tgt_len] ''' attn_shape = [seq.size(0 ), seq.size(1 ), seq.size(1 )] subsequence_mask = np.triu(np.ones(attn_shape), k=1 ) subsequence_mask = torch.from_numpy(subsequence_mask).byte() return subsequence_mask get_attn_subsequence_mask(dec_inputs)
与输入Attention做计算
这里需要指出的是,对输入层中padding的token,也需要做一步掩码操作,避免梯度计算。代码实现如下所示:
对输入token=0的位置
1 2 3 4 5 6 7 8 9 10 11 12 def get_attn_pad_mask (seq_q, seq_k ): ''' seq_q: [batch_size, seq_len] seq_k: [batch_size, seq_len] seq_len could be src_len or it could be tgt_len seq_len in seq_q and seq_len in seq_k maybe not equal ''' batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() pad_attn_mask = seq_k.data.eq(0 ).unsqueeze(1 ) return pad_attn_mask.expand(batch_size, len_q, len_k)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class DecoderLayer (nn.Module ): def __init__ (self ): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward (self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask ): ''' dec_inputs: [batch_size, tgt_len, d_model] enc_outputs: [batch_size, src_len, d_model] dec_self_attn_mask: [batch_size, tgt_len, tgt_len] dec_enc_attn_mask: [batch_size, tgt_len, src_len] ''' dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) return dec_outputs, dec_self_attn, dec_enc_attn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Decoder (nn.Module ): """解码层""" def __init__ (self ): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(target_vocab_size, d_model) self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward (self, dec_inputs, enc_inputs, enc_outputs ): ''' dec_inputs: [batch_size, tgt_len] enc_intpus: [batch_size, src_len] enc_outputs: [batsh_size, src_len, d_model] ''' dec_outputs = self.tgt_emb(dec_inputs) dec_outputs = self.pos_emb(dec_outputs.transpose(0 , 1 )).transpose(0 , 1 ).cuda() dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0 ).cuda() dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_outputs, dec_self_attns, dec_enc_attns
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Transformer (nn.Module ): def __init__ (self ): super(Transformer, self).__init__() self.encoder = Encoder().cuda() self.decoder = Decoder().cuda() self.projection = nn.Linear(d_model, target_vocab_size, bias=False ).cuda() def forward (self, enc_inputs, dec_inputs ): ''' enc_inputs: [batch_size, src_len] dec_inputs: [batch_size, tgt_len] ''' enc_outputs, enc_self_attns = self.encoder(enc_inputs) dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) dec_logits = self.projection(dec_outputs) return dec_logits.view(-1 , dec_logits.size(-1 )), enc_self_attns, dec_self_attns, dec_enc_attns
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 model = Transformer().cuda() criterion = nn.CrossEntropyLoss(ignore_index=0 ) optimizer = optim.SGD(model.parameters(), lr=1e-3 , momentum=0.99 ) for epoch in range(1000 ): for enc_inputs, dec_inputs, dec_outputs in loader: ''' enc_inputs: [batch_size, src_len] dec_inputs: [batch_size, tgt_len] dec_outputs: [batch_size, tgt_len] ''' enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda() outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs) loss = criterion(outputs, dec_outputs.view(-1 )) print('Epoch:' , '%04d' % (epoch + 1 ), 'loss =' , '{:.6f}' .format(loss)) optimizer.zero_grad() loss.backward() optimizer.step()
Transformer论文逐段精读【论文精读】 Transformer模型Encoder原理精讲及其PyTorch逐行实现 详解Transformer The Illustrated Transformer Self-Attention和Transformer 放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较










{kind=link}